Centralized Logging with OpenSearch
Overview
Centralized Logging with OpenSearch provides a robust solution for aggregating, processing, and visualizing log data across diverse sources using Amazon OpenSearch Service. This AWS solution includes a web-based management console that simplifies the creation of log ingestion pipelines through an intuitive interface.
The log ingestion pipelines support key functionalities, such as deploying log collection agents, enriching log data without requiring custom code, implementing a buffering layer for scalable log processing, and configuring OpenSearch indices to optimize search and analytics performance. Once ingested, logs are stored in the OpenSearch Service, where pre-configured dashboards are automatically generated to facilitate the analysis of AWS service logs and application logs, including formats like Nginx, JSON, and Spring Boot.
By leveraging integration with other AWS services, this solution delivers a fully managed, scalable environment for centralized logging, enabling organizations to efficiently monitor and analyze their AWS applications and infrastructure.
Technical Details
Each architecture has unique advantages and considerations to support different logging scenarios effectively. Below are the workflows and technical details for various scenarios:
Scenario 1: Logs to Amazon S3 Directly (OpenSearch Engine)
Applicable Log Sources:
- AWS CloudTrail logs
- Application Load Balancer access logs
- AWS WAF logs
- Amazon CloudFront standard logs
- Amazon S3 Access Logs
- AWS Config logs
- VPC Flow Logs

Workflow
- AWS services are configured to deliver logs directly to an Amazon S3 bucket (Log Bucket).
- Option A: An event notification is sent to Amazon EventBridge upon log file creation.
- EventBridge triggers the Log Processor Lambda function.
- Option B: An event notification is sent to Amazon SQS using S3 Event Notifications.
- The OpenSearch Ingestion Service consumes SQS messages.
- The Log Processor Lambda function processes log files and ingests them into Amazon OpenSearch Service.
- Failed log processing outputs are stored in a Backup Bucket.
Advantages:
- Simple setup for supported AWS services.
- Cost-effective for low-volume logs.
- Native integration with Amazon S3 and OpenSearch.
Disadvantages:
- Limited to services capable of direct S3 delivery.
- Higher latency compared to real-time ingestion.
Scenario 2: Logs to Amazon S3 via Firehose (OpenSearch Engine)
Applicable Log Sources:
- Amazon RDS/Aurora logs
- AWS Lambda logs

Workflow:
- AWS services deliver logs to Amazon CloudWatch Logs.
- Amazon Kinesis Data Firehose subscribes to CloudWatch Log Groups and delivers logs to Amazon S3 (Log Bucket).
- S3 Event Notifications send events to Amazon SQS when a new log file is created.
- SQS triggers the Log Processor Lambda function.
- The Lambda function processes logs and ingests them into Amazon OpenSearch Service.
- Failed logs are exported to the Backup Bucket.
Advantages:
- Supports services that cannot deliver logs directly to S3.
- Reliable buffering and delivery through Firehose.
Disadvantages:
- Additional cost for Firehose.
- Slightly higher latency due to intermediate steps.
Scenario 3: Logs to Amazon S3 via API (OpenSearch Engine)
Applicable Log Sources:
- Amazon RDS
- AWS WAF (Sampled Logs)

Workflow:
- Amazon EventBridge triggers a helper Lambda function periodically (default: every 5 minutes).
- The Lambda function calls AWS service APIs to fetch log files.
- Retrieved logs are stored in the Log Bucket.
- Event notifications trigger the Log Processor Lambda function via EventBridge.
- The Lambda function processes and ingests logs into OpenSearch Service.
- Failed logs are moved to the Backup Bucket.
Advantages:
- Enables log collection for services without native delivery to S3 or CloudWatch.
- Periodic API calls ensure timely log ingestion.
Disadvantages:
- Increased operational overhead due to periodic API polling.
- Potential cost implications for frequent Lambda invocations.
Scenario 4: Logs to Amazon S3 Directly (Light Engine)
Applicable Log Sources:
- Amazon CloudFront standard logs
- AWS CloudTrail logs
- Application Load Balancer access logs
- AWS WAF logs
- VPC Flow Logs

Workflow:
- AWS services deliver logs directly to the Log Bucket.
- S3 Event Notifications send events to Amazon SQS.
- SQS triggers the Log Processor Lambda function.
- Lambda retrieves logs and uploads them to a Staging Bucket.
- AWS Step Functions processes logs in batches from the Staging Bucket.
- Logs are converted to Apache Parquet format, partitioned, and stored in the Centralized Bucket.
Advantages:
- Efficient data processing using Apache Parquet format.
- Cost-effective storage and analytics for large-scale logs.
Disadvantages:
- Increased complexity with additional services like Step Functions.
- Higher initial setup effort.
Scenario 5: Logs to Kinesis Data Streams Directly (OpenSearch Engine)
Applicable Log Sources:
- Amazon CloudFront real-time logs
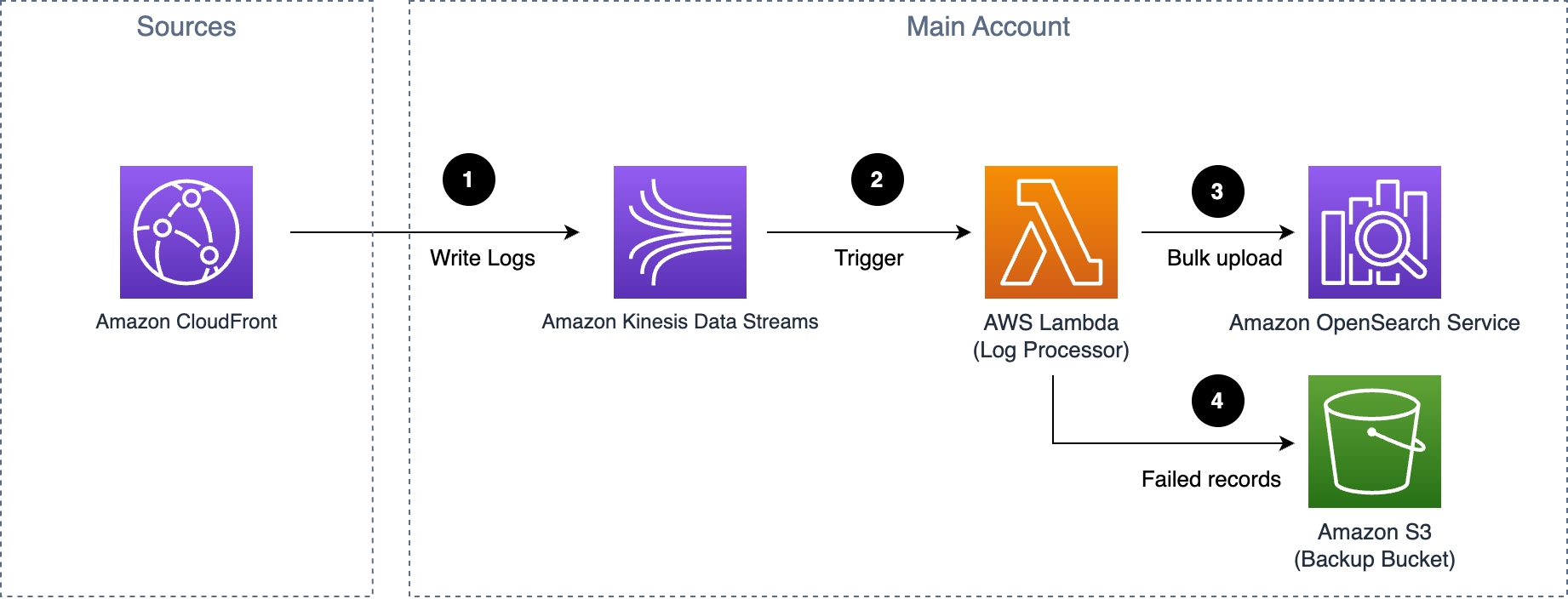
Workflow:
- AWS services deliver logs directly to Amazon Kinesis Data Streams.
- Kinesis Data Streams trigger a Lambda function to process logs.
- The Lambda function ingests logs into OpenSearch Service.
- Failed logs are exported to the Backup Bucket.
Advantages:
- Real-time log ingestion.
- Scalable and low-latency processing.
Disadvantages:
- Higher operational costs for real-time processing.
- Does not support cross-account ingestion for CloudFront logs.
Scenario 6: Logs to Kinesis Data Streams via CloudWatch Logs
Applicable Log Sources:
- AWS CloudTrail logs
- VPC Flow Logs

Workflow:
- AWS services deliver logs to CloudWatch Logs.
- Logs are forwarded to Kinesis Data Streams using CloudWatch Log subscriptions.
- Kinesis Data Streams trigger a Log Processor Lambda function.
- Logs are processed and ingested into OpenSearch Service.
- Failed logs are sent to the Backup Bucket.
Advantages:
- Enables real-time ingestion for CloudWatch Log sources.
- Supports diverse log sources with minimal latency.
Disadvantages:
- Higher costs for Kinesis Data Streams and associated services.
- Additional configuration required for CloudWatch Log subscriptions.
Cost-Effectiveness Analysis

Recommendation:
- Use Logs to S3 Directly for simple and cost-efficient workflows with supported log sources.
- For real-time analytics, consider Logs to Kinesis Data Streams but evaluate cost trade-offs.
- Use Logs to S3 via API or via Firehose for unsupported services or complex requirements.
