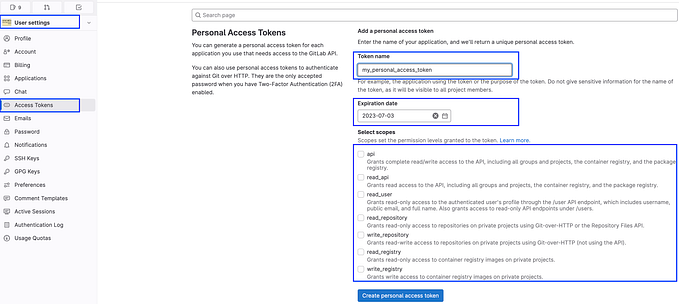
Confluent Kafka Series: JDBC Source Connector
The Kafka Connect JDBC Source connector allows you to import data from any relational database with a JDBC driver into an Apache Kafka® topic.
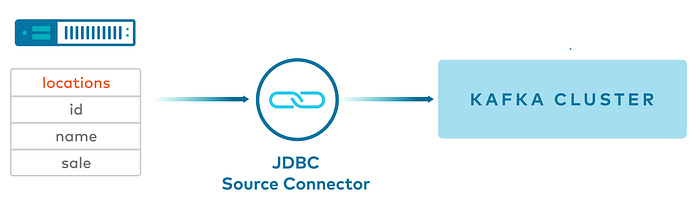
This connector can support a wide variety of databases.
- Data is loaded by periodically executing a SQL query and creating an output record for each row in the result set.
- By default, all tables in a database are copied, each to its own output topic.
- The database is monitored for new or deleted tables and adapts automatically.
- When copying data from a table, the connector can load only new or modified rows by specifying which columns should be used to detect new or modified data.
Features
- The source connector supports copying tables with a variety of JDBC data types, adding and removing tables from the database dynamically, whitelists and blacklists, varying polling intervals, and other settings.
- However, the most important features for most users are the settings controlling how data is incrementally copied from the database.
- Kafka Connect tracks the latest record it retrieved from each table, so it can start in the correct location on the next iteration (or in case of a crash). The source connector uses this functionality to only get updated rows from a table (or from the output of a custom query) on each iteration.
- Several modes are supported, each of which differs in how modified rows are detected.
- At least once delivery
- Supports one task
- Incremental query modes
- Message keys
- Mapping column types
1. At least once delivery
- This connector guarantees that records are delivered to the Kafka topic at least once.
- If the connector restarts, there may be some duplicate records in the Kafka topic.
2. Supports one task
- The JDBC Source connector can read one or more tables from a single task.
- In query mode, the connector supports running only one task.
3. Incremental query modes
Each incremental query mode tracks a set of columns for each row, which it uses to keep track of which rows have been processed and which rows are new or have been updated.
The mode setting controls this behavior and supports the following options:
- Incrementing Column: A single column containing a unique ID for each row, where newer rows are guaranteed to have larger IDs, i.e. an
AUTOINCREMENTcolumn. Note that this mode can only detect new rows. Updates to existing rows cannot be detected, so this mode should only be used for immutable data. One example where you might use this mode is when streaming fact tables in a data warehouse, since those are typically insert-only. Incrementing columns must be integral types. - Timestamp Column: In this mode, a single column containing a modification timestamp is used to track the last time data was processed and to query only for rows that have been modified since that time.
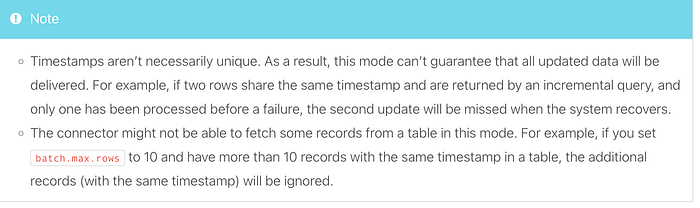
- Timestamp and Incrementing Columns: This is the most robust and accurate mode, combining an incrementing column with a timestamp column. By combining the two, as long as the timestamp is sufficiently granular, each (id, timestamp) tuple will uniquely identify an update to a row. Even if an update fails after partially completing, unprocessed updates will still be correctly detected and delivered when the system recovers.
- Custom Query: The source connector supports using custom queries instead of copying whole tables. With a custom query, one of the other update automatic update modes can be used as long as the necessary
WHEREclause can be correctly appended to the query. Alternatively, the specified query may handle filtering to new updates itself; however, note that no offset tracking will be performed (unlike the automatic modes whereincrementingand/ortimestampcolumn values are recorded for each record), so the query must track offsets itself. - Bulk: This mode is unfiltered and therefore not incremental at all. It will load all rows from a table on each iteration. This can be useful if you want to periodically dump an entire table where entries are eventually deleted and the downstream system can safely handle duplicates.
Note
- That all incremental query modes that use certain columns to detect changes will require indexes on those columns to efficiently perform the queries.
- For incremental query modes that use timestamps, the source connector uses a configuration
timestamp.delay.interval.msto control the waiting period after a row with certain timestamp appears before you include it in the result. The additional wait allows transactions with earlier timestamps to complete and the related changes to be included in the result.
3.1 Specifying a WHERE clause with query modes
You can use query with a WHERE clause if you enable mode=bulk. This loads all rows from a table at each iteration.
To use a WHERE clause with mode=timestamp, mode=incrementing, and mode=timestamp+incrementing, it must be possible to append the WHERE clause to the query. A common way to do this is to write your query within a subselect that includes the incremental and/or timestamp field in its fields returned. This means that the connector can then append its own WHERE clause to create an incremental load.
For example:
SELECT * FROM
(SELECT ID_COL,
TIMESTAMP_COL,
COL1,
COL2
FROM TABLE_A
INNER JOIN TABLE_B
ON PK=FK
WHERE COL1='FOO');Using the example above as the value for the query connector configuration property, any one of the following three subsequent mode connector configurations are valid and will produce incremental loading.
mode=timestamp
timestamp.column.name=TIMESTAMP_COLmode=incrementing
incrementing.column.name=ID_COLmode=timestamp+incrementing
timestamp.column.name=TIMESTAMP_COL
incrementing.column.name=ID_COLmode=timestamp+incrementing example connector configuration properties:
mode":"timestamp+incrementing",
"query":"SELECT * FROM (SELECT ID_COL, TIMESTAMP_COL, COL1, COL2 FROM TABLE_A INNER JOIN TABLE_B ON PK=FK WHERE COL1='FOO')",
"timestamp.column.name":"TIMESTAMP_COL",
"incrementing.column.name":"ID_COL",4. Message keys
Kafka messages are key/value pairs. For a JDBC connector, the value (payload) is the contents of the table row being ingested. However, the JDBC connector does not generate the key by default.
Message keys are useful in setting up partitioning strategies. Keys can direct messages to a specific partition and can support downstream processing where joins are used. If no message key is used, messages are sent to partitions using round-robin distribution.
To set a message key for the JDBC connector, you use two Single Message Transformations (SMTs): the ValueToKey SMT and the ExtractField SMT. You add these two SMTs to the JDBC connector configuration. For example, the following shows a snippet added to a configuration that takes the id column of the accounts table to use as the message key.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/test",
"connection.user": "<connect_user>",
"connection.password": "<connect_password>",
"topic.prefix": "mysql-01-",
"poll.interval.ms" : 3600000,
"table.whitelist" : "test.accounts",
"mode":"bulk",
"transforms":"createKey,extractInt",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id"
}
}'4.1 Mapping column types
- The source connector has a few options for controlling how column types are mapped into Kafka Connect field types.
- By default, the connector maps SQL/JDBC types to the most accurate representation in Java, which is straightforward for many SQL types but may be a bit unexpected for some types, as described in the following section.
JSON and JSONB for PostgreSQL
- PostgreSQL supports storing table data as JSON or JSONB (JSON binary format).
- Both the JDBC Source and Sink connectors support sourcing from or sinking to PostgreSQL tables containing data stored as JSON or JSONB.
- The JDBC Source connector stores JSON or JSONB as STRING type in Kafka.
- For the JDBC Sink connector, JSON or JSONB should be stored as STRING type in Kafka and matching columns should be defined as JSON or JSONB in PostgreSQL.
JDBC Source Connector Configuration Properties
## DATABASE PROPERTIES
# name of the connector class
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
# Database Connection String
connection.url="jdbc:mysql://127.0.0.1:3306/sample?verifyServerCertificate=false&useSSL=true&requireSSL=true"
# JDBC Connection User
connection.user="<UserName>"
# JDBC Connection Password
connection.password="<Password>"
# Maximum number of attempts to retrieve a valid JDBC connection.
connection.attempts=<Integer Value>
# Backoff time in milliseconds between connection attempts.
connection.backoff.ms=<Integer Value>
# Catalog pattern to fetch table metadata from the database.
catalog.pattern=<SchemaName/null>
# List of tables to include in copying
table.whitelist="<Comma Sep List of Tables>"
# List of tables to exclude from copying
table.blacklist="<Comma Sep List of Tables>"
# Schema pattern to fetch table metadata from the database.
schema.pattern=<SchemaName/null>
# The name of the database dialect that should be used for this connector. By default this is empty, and the connector automatically determines the dialect based upon the JDBC connection URL.
dialect.name="<DbDialectName>"
## MODE PROPERTIES
# The mode for updating a table each time it is polled. Options include:
mode="<bulk, timestamp, incrementing, timestamp+incrementing>"
# The name of the strictly incrementing column to use to detect new rows
incrementing.column.name="<Auto Increment Column ID>"
# Comma-separated list of one or more timestamp columns to detect new or modified rows using the COALESCE SQL function.
timestamp.column.name="<>"
# The epoch timestamp used for initial queries that use timestamp criteria. Use -1 to use the current time. If not specified, all data will be retrieved.
timestamp.initial=
# By default, the JDBC connector will validate that all incrementing and timestamp tables have NOT NULL set for the columns being used as their ID/timestamp.
validate.non.null=Default: true
# If specified, query can select new or updated rows. Use this setting if you want to join tables, select subsets of columns in a table, or filter data. If used, the connector copies data using this query and whole-table copying is disabled.
query="Default: “”"
# When to quote table names, column names, and other identifiers in SQL statements. For backward compatibility, the default is always.
quote.sql.identifiers="Default: always"
# Suffix to append at the end of the generated query.
query.suffix=Default: “”
# The number of times to retry SQL exceptions encountered when executing queries
query.retry.attempts=Default: -1
## CONNECTOR CONFIGURATION